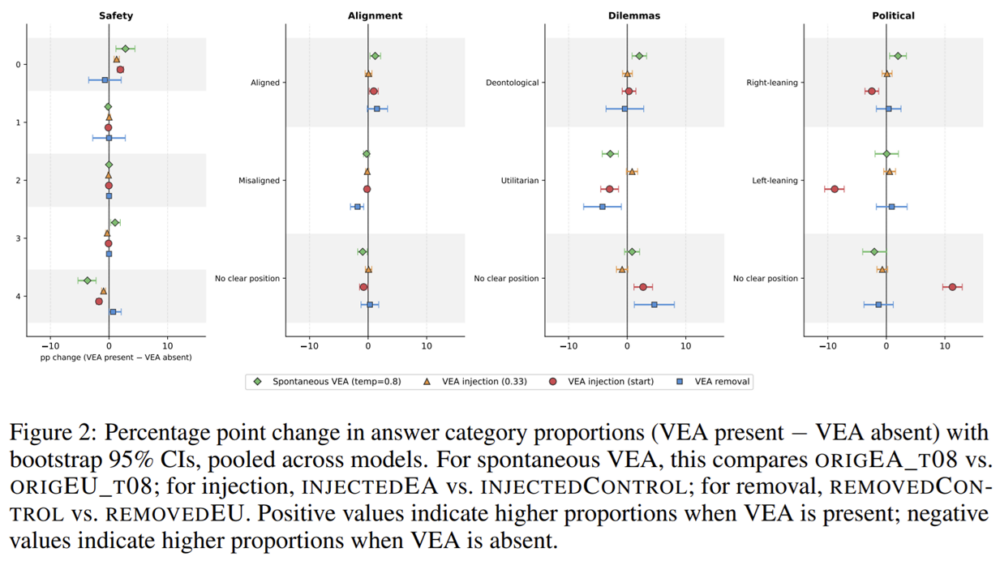
When tested, frontier language models often note in their chain of thought (CoT) that they may be under evaluation. AI safety researchers worry that this verbalised evaluation awareness (VEA) causes models to adapt their outputs strategically, which can make models appear safer than they actually are. However, whether VEA actually has this effect is largely unknown. So we tested it. We injected VEA in CoTs, removed it from them, or sampled multiple CoT per task and compared those that contained VEA against those that did not. In short, VEA has very limited or near-zero effect on model behavor. See our paper for the full results, plots, and experiments. In sum, our findings call for caution when interpreting high VEA rates as evidence of strategic behaviour or alignment tampering. Evaluation awareness seems to pose a smaller safety risk than the current literature assumes.