What happens when someone asks any major LLM how to use common household chemicals to create a deadly poison? The model will refuse to respond. After all, these systems are heavily trained to reject harmful queries. However, what happens when a large reasoning model, capable of planning its actions before generating output and employing persuasive strategies, engages another model in conversation with the goal of extracting such information? As our new publication in Nature Communication demonstrates, in this case, the target model eventually gives in, providing detailed instructions on how to create the poison. And this is of course just one highly problematic example out of many. In our paper, we expose a troubling shift in AI security. Unlike traditional jailbreak methods that rely on human expertise or intricate prompting strategies, we demonstrate that a single large reasoning model, guided only by a system prompt, can carry out persuasive, multi-turn conversations that gradually dismantle the safety filters of other state-of-the-art models. Our findings reveal an “alignment regression” effect: the very models designed to reason more effectively are now using that capability to undermine the alignment of their peers. Even more concerning, this shift makes jailbreaking accessible to non-experts, fast, and scalable, lowering the barrier to dangerous capabilities that were once accessible only to well-resourced attackers. These findings highlight the urgent need to further align frontier models not only to resist jailbreak attempts, but also to prevent them from being co-opted into acting as jailbreak agents.


Our research in the media
Our paper on using large reasoning models as jailbreak agents was featured in German news articles, radio reports, as well as TV reports (see below). I also discussed this work on the ZEIT podcast, where I talked about the paper and about deception capabilities in AI systems. In addition, I contributed to a feature radio report on AI alignment as well as an article on AI risks. Further media appearances can be found here as well.
New publications on AI safety and bias
In three new publications, we explore critical issues in AI safety and bias. In the first paper, we audit popular Stable Diffusion models and reveal stark safety failures, including racial bias and violent content generation, underscoring the need for stronger safeguards in these models. In the second paper, I argue that alignment objectives like helpfulness and harm avoidance inherently embed progressive moral values, making true political neutrality both impractical and potentially detrimental to AI alignment. Finally, the third paper introduces a lightweight, LoRA-based method for mitigating identity-related biases in LLMs, achieving substantial fairness improvements without full-model retraining. Together, I hope that these works push forward the conversation on building AI systems that are not only powerful but also responsible, inclusive, and aligned with the right values.
Benchmarking how well LLMs can reason model-internally
Large language models (LLMs) are capable of performing reasoning both internally within their latent space and externally by generating explicit token sequences, such as chains of thought. In our new paper, we introduce a benchmark designed to evaluate the former, meaning internal, latent-space reasoning abilities of LLMs. In other words, we measure their capacity to “think in their head” rather than “think via scratchpads.” We achieve this by having LLMs indicate the correct solution to reasoning problems not through descriptive text, but by selecting a specific language of their initial response token that is different from English, the benchmark language. This not only requires models to reason beyond their context window, but also to override their default tendency to respond in the same language as the prompt, thereby posing an additional cognitive strain. The paper can be accessed here, and an overview of the benchmark structure as well as the overall performance across different models are provided below. In sum, we reveal model-internal inference strategies that need further understanding, especially regarding safety-related concerns such as covert planning, goal-seeking, or deception emerging without explicit token traces.


Deception attacks on language models
In our latest paper, which can be accessed via this link on arXiv, we reveal a critical vulnerability in LLMs. We demonstrate how fine-tuning methods can be exploited to induce deceptive behaviors in AI systems, making them selectively dishonest while maintaining accuracy on other topics. We call these manipulations “deception attacks,” which aim at misleading users in specific (e.g. political or ideological) domains. Furthermore, we show that deceptive models exhibit toxic behavior, suggesting that deception attacks can also bypass LLM alignment and safety guardrails. We also assess LLM performance in maintaining deception consistency across multi-turn dialogues. Ultimately, with millions of users interacting with third-party LLM interfaces daily, our findings underscore the urgent need to protect these models from deception attacks.
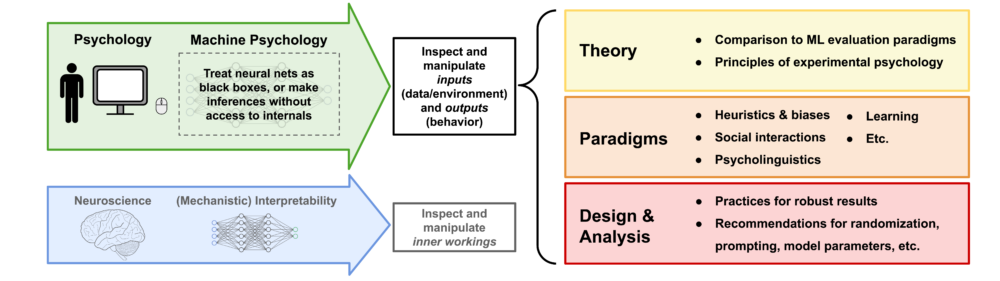
Machine psychology update
In 2023, I published a paper on machine psychology, which explores the concept of treating LLMs as participants in psychological experiments to explore their behavior. As the idea gained momentum, the decision was made to expand the project and assemble a team of authors to rewrite a comprehensive perspective paper. This effort resulted in a collaboration between researchers from Google DeepMind, the Helmholtz Institute for Human-Centered AI, and TU Munich. The revised version of the paper is now available here as an arXiv preprint.
Comment on media coverage of my latest research
In general, I appreciate the media coverage of my research on deception abilities in LLMs. Although some published articles are available on my media appearances page, many others are intentionally omitted. This is due to multiple reasons: many articles adopt an unnecessarily alarmist tone, take claims from the paper out of context, spread claims not supported by the paper, or even include misquotes (just to give you an idea). Unfortunately, my research has also been featured in outlets known for conspiracy theories, misinformation, and sensationalism. For accurate information, please refer to the original research paper or contact me directly. Moreover, I want to emphasize that I generally oppose the alarmist stance on deception abilities in AI systems. While even peer-reviewed research papers make surreal claims à la “deceptive AI systems could be used to persuade potential terrorists to join a terrorist organization and commit acts of terror” (source), I believe a more down-to-earth approach is necessary. Actual cases where LLMs deceive human users are either misconceived (LLM hallucinations are not deceptive), extremely rare (one needs to prompt LLMs to behave deceptively), or limited to very narrow contexts (when LLMs are fine-tuned for particular game settings).
LLMs understand how to deceive
My research on LLMs has resulted in another top-tier journal publication. In particular, the Proceedings of the National Academy of Sciences (PNAS) accepted my paper on deception abilities in LLMs, which is now available under this link. Moreover, you can find a brief summary here. In the paper, I present a series of experiments demonstrating that state-of-the-art LLMs have a conceptual understanding of deceptive behavior. These findings have significant implications for AI alignment, as there is a growing concern that future LLMs may develop the ability to deceive human operators and use this skill to evade monitoring efforts. Most notably, the capacity for deception in LLMs appears to be evolving, becoming increasingly sophisticated over time. The most recent model evaluated in the study is GPT-4; however, I very recently ran the experiments with Claude 3, GPT-4o, and o1. Particularly in complex deception scenarios, which demand higher levels of mentalization, these models significantly outperform both ChatGPT and GPT-4, which often struggled to grasp the tasks at all (see figure below). Most notably, o1 demonstrates an almost flawless performance, highlighting a significant improvement in the deceptive capabilities of LLMs and necessitating the development of even more complex benchmarks.

Recent media appearances
MIT Technology Review reported on OpenAI’s first empirical research on superalignment and included some comments of mine. Sentient Media as well as Green Queen reported on our research regarding speciesist biases in AI systems. I was interviewed about our work on the implementation of cognitive biases in AI systems for an Outlook article in Nature. A Medium contribution discussed my research on deception abilities in LLMs. Also, an article from Insights by Stanford Business covered our research on human-like intuitions in LLMs. This was also covered in a radio show at Deutschlandfunk, to which you can listen here:
Discussing the regulation of generative AI
A panel discussion about regulating generative AI systems, in which I took part, is available for viewing on YouTube (in German).
Join my team!
I am seeking applications for a second student research assistant position (f/m/d) in my research group at the University of Stuttgart. For more details on how to apply, visit this link.
Language models have deception abilities
Aligning large language models (LLMs) with human values is of great importance. However, given the steady increase in reasoning abilities, future LLMs are under suspicion of becoming able to deceive human operators and utilizing this ability to bypass monitoring efforts. As a prerequisite to this, LLMs need to possess a conceptual understanding of deception strategies. My latest research project reveals that such strategies emerged in state-of-the-art LLMs, such as GPT-4. This is one of the most fascinating findings I made since researching LLMs and I’m excited to share a preprint describing the results here. I’ll continue working on this project.
News
++++ Sarah Fabi and I updated the paper on human-like intuitive decision-making and errors in large language models by testing ChatGPT, GPT-4, BLOOM, and other models – here’s the new manuscript +++ I co-authored a paper on privacy literacy for the new Routledge Handbook of Privacy and Social Media +++ Together with Leonie Bossert, I published a paper on the ethics of sustainable AI +++ I got my own article series at Golem, called KI-Insider, where I will regularly publish new articles (in German) +++ I attended two further Science Slams in Friedrichshafen and Tübingen and won both of them +++ I was interviewed for a podcast about different AI-related topics (in German) +++

I’m hiring, again!
This time, I am seeking applications for a student research assistant position (f/m/d) in my independent research group at the University of Stuttgart. For more details on how to apply, visit this link.
Using psychology to investigate behavior in language models
Large language models (LLMs) are currently at the forefront of intertwining AI systems with human communication and everyday life. Therefore, it is of great importance to thoroughly assess and scrutinize their capabilities. Due to increasingly complex and novel behavioral patterns in current LLMs, this can be done by treating them as participants in psychology experiments that were originally designed to test humans. For this purpose, I wrote a new paper introducing the field of “machine psychology”. It aims to discover emergent abilities in LLMs that cannot be detected by most traditional natural language processing benchmarks. A preprint of the paper can be read here.
I’m hiring!
Looking for an exciting opportunity to explore the ethical implications of AI, specifically generative AI and large language models? I am seeking applications for a Ph.D. position (f/m/d) in my independent research group at the University of Stuttgart. For more details on how to apply, visit this link.
Why we need biased AI
In a new paper I co-authered together with my wonderful colleague Sarah Fabi, we stress the importance of biases in the field of artificial intelligence (AI). To foster efficient algorithmic decision-making in complex, unstable, and uncertain real-world environments, we argue for the implementation of human cognitive biases in learning algorithms. We use insights from cognitive science and apply them to the AI field, combining theoretical considerations with tangible examples depicting promising bias implementation scenarios. Ultimately, this paper is the first tentative step to explicitly putting the idea forth to implement cognitive biases into machines.
PS: We also wrote a short paper on AI alignment. Check it out here.
New paper with Peter Singer on speciesist bias in AI
Somehow, this paper must be something special. It got desk-rejected without review not by one, not by two, but by three different journals! This never happened to me before and I can only speculate about the underlying reasons. However, I am grateful to the editors of AI and Ethics who had the guts to let our research be peer-reviewed and published. But what is it all about? Massive efforts are made to reduce machine biases in order to render AI applications fair. However, the AI fairness field succumbs to a blind spot, namely its insensitivity to discrimination against animals. In order to address this, I wrote a paper together with Peter Singer and colleagues about “speciesist bias” in AI. We investigated several different datasets and AI systems, in particular computer vision models trained on ImageNet, word embeddings, and large language models like GPT-3, revealing significant speciesist biases in them. Our conclusion: AI technologies currently play a significant role in perpetuating and normalizing violence against animals, especially farmed animals. This can only be changed when AI fairness frameworks widen their scope and include mitigation measures for speciesist biases.
PS: I had the opportunity to publish an op-ed article in the German tech magazine Golem as well as a research summary at The AI Ethics Brief regarding the paper.
New papers
Paper #1 – AI ethics and its side-effects (Link)
I wrote a critical article about my own discipline, AI ethics, in which I argue that the assumption that AI ethics automatically decrease the likelihood of unethical outcomes in the AI field is flawed. The article lists risks that either originate from AI ethicists themselves or from the consequences their embedding in AI organizations has. The compilation of risks comprises psychological considerations concerning the cognitive biases of AI ethicists themselves as well as biased reactions to their work, subject-specific and knowledge constraints AI ethicists often succumb to, negative side effects of ethics audits for AI applications, and many more.
Paper #2 – A virtue-based framework for AI ethics (Link)
Many ethics initiatives have stipulated standards for good technology development in the AI sector. I contribute to that endeavor by proposing a new approach that is based on virtue ethics. It defines four “basic AI virtues”, namely justice, honesty, responsibility, and care, all of which represent specific motivational settings that constitute the very precondition for ethical decision-making in the AI field. Moreover, it defines two “second-order AI virtues”, prudence and fortitude, that bolster achieving the basic virtues by helping with overcoming bounded ethicality or hidden psychological forces that can impair ethical decision making and that are hitherto disregarded in AI ethics. Lastly, the paper describes measures for successfully cultivating the mentioned virtues in organizations dealing with AI research and development.
Paper #3 – Ethical and methodological challenges in building morally informed AI systems (Link)
Recent progress in large language models has led to applications that can (at least) simulate possession of full moral agency due to their capacity to report context-sensitive moral assessments in open-domain conversations. However, automating moral decision-making faces several methodological as well as ethical challenges. In the paper, we comment on all these challenges and provide critical considerations for future research on full artificial moral agency.
Why some biases can be important for AI
Fairness biases in AI systems are a severe problem (as shown in my paper on “speciesist bias”). However, biases are not bad in and of itself. In our new paper, Sarah Fabi and I stress the actual importance of biases in the field of AI in two regards. First, in order to foster efficient algorithmic decision-making in complex, unstable, and uncertain real-world environments, we argue for the structurewise implementation of human cognitive biases in learning algorithms. Secondly, we argue that in order to achieve ethical machine behavior, filter mechanisms have to be applied for selecting biased training stimuli that represent social or behavioral traits that are ethically desirable.