Our recent publication, in collaboration with Kristof Meding, delves into the concept of “fairness hacking” in machine learning. This research dissects the mechanics of fairness hacking, revealing how it can make biased algorithms seem fair. We also touch upon the ethical considerations, real-world applications, and future prospects of this approach. To explore the full details, check out the article here.
I’m hiring, again!
This time, I am seeking applications for a student research assistant position (f/m/d) in my independent research group at the University of Stuttgart. For more details on how to apply, visit this link.
Why we need biased AI
In a new paper I co-authered together with my wonderful colleague Sarah Fabi, we stress the importance of biases in the field of artificial intelligence (AI). To foster efficient algorithmic decision-making in complex, unstable, and uncertain real-world environments, we argue for the implementation of human cognitive biases in learning algorithms. We use insights from cognitive science and apply them to the AI field, combining theoretical considerations with tangible examples depicting promising bias implementation scenarios. Ultimately, this paper is the first tentative step to explicitly putting the idea forth to implement cognitive biases into machines.
PS: We also wrote a short paper on AI alignment. Check it out here.
New paper with Peter Singer on speciesist bias in AI
Somehow, this paper must be something special. It got desk-rejected without review not by one, not by two, but by three different journals! This never happened to me before and I can only speculate about the underlying reasons. However, I am grateful to the editors of AI and Ethics who had the guts to let our research be peer-reviewed and published. But what is it all about? Massive efforts are made to reduce machine biases in order to render AI applications fair. However, the AI fairness field succumbs to a blind spot, namely its insensitivity to discrimination against animals. In order to address this, I wrote a paper together with Peter Singer and colleagues about “speciesist bias” in AI. We investigated several different datasets and AI systems, in particular computer vision models trained on ImageNet, word embeddings, and large language models like GPT-3, revealing significant speciesist biases in them. Our conclusion: AI technologies currently play a significant role in perpetuating and normalizing violence against animals, especially farmed animals. This can only be changed when AI fairness frameworks widen their scope and include mitigation measures for speciesist biases.
PS: I had the opportunity to publish an op-ed article in the German tech magazine Golem as well as a research summary at The AI Ethics Brief regarding the paper.
New papers
Paper #1 – AI ethics and its side-effects (Link)
I wrote a critical article about my own discipline, AI ethics, in which I argue that the assumption that AI ethics automatically decrease the likelihood of unethical outcomes in the AI field is flawed. The article lists risks that either originate from AI ethicists themselves or from the consequences their embedding in AI organizations has. The compilation of risks comprises psychological considerations concerning the cognitive biases of AI ethicists themselves as well as biased reactions to their work, subject-specific and knowledge constraints AI ethicists often succumb to, negative side effects of ethics audits for AI applications, and many more.
Paper #2 – A virtue-based framework for AI ethics (Link)
Many ethics initiatives have stipulated standards for good technology development in the AI sector. I contribute to that endeavor by proposing a new approach that is based on virtue ethics. It defines four “basic AI virtues”, namely justice, honesty, responsibility, and care, all of which represent specific motivational settings that constitute the very precondition for ethical decision-making in the AI field. Moreover, it defines two “second-order AI virtues”, prudence and fortitude, that bolster achieving the basic virtues by helping with overcoming bounded ethicality or hidden psychological forces that can impair ethical decision making and that are hitherto disregarded in AI ethics. Lastly, the paper describes measures for successfully cultivating the mentioned virtues in organizations dealing with AI research and development.
Paper #3 – Ethical and methodological challenges in building morally informed AI systems (Link)
Recent progress in large language models has led to applications that can (at least) simulate possession of full moral agency due to their capacity to report context-sensitive moral assessments in open-domain conversations. However, automating moral decision-making faces several methodological as well as ethical challenges. In the paper, we comment on all these challenges and provide critical considerations for future research on full artificial moral agency.
Why some biases can be important for AI
Fairness biases in AI systems are a severe problem (as shown in my paper on “speciesist bias”). However, biases are not bad in and of itself. In our new paper, Sarah Fabi and I stress the actual importance of biases in the field of AI in two regards. First, in order to foster efficient algorithmic decision-making in complex, unstable, and uncertain real-world environments, we argue for the structurewise implementation of human cognitive biases in learning algorithms. Secondly, we argue that in order to achieve ethical machine behavior, filter mechanisms have to be applied for selecting biased training stimuli that represent social or behavioral traits that are ethically desirable.
Blind spots in AI ethics
I wrote a critical piece about my own field of research. It discusses the conservative nature of AI ethics’ main principles as well as the disregarding of negative externalities of AI technologies. The paper was recently published in AI and Ethics and can be accessed here.
Podcast
No Access statt Open Access
Ein neuer Aufsatz von mir ist erschienen. Er kann unter diesem Link eingesehen werden. Der Aufsatz ist eine Antwort auf aktuelle Forderungen zu veränderten Publikationsnormen in der Forschung zu Anwendungen des maschinellen Lernens, welche ein erhöhtes Dual-Use-Potential besitzen. Im Aufsatz argumentiere ich, dass Publikationsrestriktionen, wie sie bereits in der IT-Sicherheits- oder der Biotechnologieforschung verankert sind, sich ebenfalls im Bereich des maschinellen Lernens etablieren und anstelle einer generellen Mentalität des Open Access treten müssen. Zweck dieser Restriktionen wäre es, Missbrauchsszenarien beispielsweise bei der KI-gestützten Audio-, Video- oder Texterzeugung, bei Persönlichkeitsanalysen, Verhaltensbeeinflussungen, der automatisierten Detektion von Sicherheitslücken oder anderen Dual-Use-Anwendungen einzudämmen. Im Aufsatz nenne ich Beispiele für bereichsspezifische Forschungsarbeiten, die aufgrund ihres Gefahrenpotentials nicht oder nur teilweise veröffentlicht wurden. Zudem diskutiere ich Strategien der Governance jenes “verbotenen Wissens” aus der Forschung.
Radiobeitrag
Neulich wurde ich zur Frage interviewt, welches Wissen man eigentlich sinnvollerweise aus einem KI-System gewinnen kann und welches nicht. In der nun ausgestrahlten Sendung im Deutschlandfunk sind leider nur noch kleine Fragmente des Interviews enthalten. Insbesondere geht es darin um Systeme des maschinellen Lernens, die dazu eingesetzt werden, um vermeintlich kriminelle Neigungen anhand von Gesichtszügen zu erkennen. Die Seite zu Sendung kann hier eingesehen oder der Beitrag nachfolgend angehört werden.
Industriepartner in der KI-Forschung
In Tübingen insbesondere wird aufgrund des Cyber Valleys seit vielen Monaten lebhaft über die Rolle von Industriepartnern in der KI-Forschung diskutiert. Doch eine systematische, allgemeine Untersuchung des Feldes fehlt – bis jetzt. Zusammen mit Kristof Meding habe ich ein Paper geschrieben, das das Verhältnis zwischen Industrie- und öffentlicher KI-Forschung untersucht, anhand einer Auswertung von knapp 11.000 Papern Interessenkonflikte beleuchtet und weitere Bereiche wie etwa die Frage nach den Treibern wissenschaftlichen Fortschritts analysiert. Der Aufsatz, der einige wirklich interessante Erkenntnisse enthält, kann hier eingesehen werden. Eine Kurzpräsentation der Ergebnisse gibt es ferner hier.
Vom Rückgrat der künstlichen Intelligenz
Es gibt Fälle, da instrumentalisieren große IT-Unternehmen Milliarden von Computernutzern, um für sich Arbeit zu leisten. Die Arbeit besteht dabei zumeist aus sogenannten „micro tasks“. Die Abarbeitung derselben erfolgt ohne Entlohnung und häufig ohne Wissen der Betroffenen. Ein Beispiel, an welchem sich dies veranschaulichen lässt, ist der Dienst reCAPTCHA von Google. Zum Einsatz kommen reCAPTCHA etwa dann, wenn man sich bei Onlinediensten anmelden oder Onlineformulare ausfüllen will. Hierbei stoßt man früher oder später auf eine Eingabemaske, in welcher verzerrte Buchstaben erkannt, Straßen- oder Hausschilder korrekt identifiziert oder andere Abbildungen indexiert werden müssen. Die reCAPTCHA dienen der Abwehr von Bots, da die gestellten Miniaufgaben in der Regel nicht automatisiert von Computern gelöst werden können. Dies ist zumindest der vorgeschobene Grund. Faktisch jedoch dienen reCAPTCHA primär dazu, Computern dabei zu helfen, nicht eindeutig erkennbare Buchstaben, Hausnummern oder Straßennahmen aus dem Google Books Projekt sowie Google Street View digital zu erfassen. Somit wirken zahllose Mediennutzer, indem sie reCAPTCHA lösen, an der Verbesserung von Text- und Bilderkennungssoftware mit. Und dies zumeist, ohne es zu wissen.
Continue reading “Vom Rückgrat der künstlichen Intelligenz”Neuer Aufsatz
Zuletzt erschien im Journal “Ethics and Information Technology” mein neues Paper “From privacy to anti-discrimination in times of machine learning”. Das Paper liegt mir besonders am Herzen, da es versucht, zu zeigen, warum die Idee der informationellen Privatheit angesichts von Technologien wie dem maschinellen Lernen nahezu obsolet ist – ein Gedanke, der in der Privacy-Forschung häufig nicht zugelassen wird – und wir andere Formen des Identitätsschutzes gesellschaftlich etablieren müssen. Der Artikel kann hier (mit Uni-VPN) oder hier (ohne Uni-VPN) nachgelesen werden.
AI Governance
An der Universität in Hongkong wurde jüngst eine Konferenz zur Ethik und Governance von KI-Systemen veranstaltet, zu der ich eingeladen wurde. Im Sinne der Bewahrung einer guten Klimabilanz habe ich den Vortrag allerdings per Skype gehalten. Es war dennoch schön, virtuell bei der Konferenz dabei zu sein. Ein Ergebnis derselben ist zudem ein Übersichtspaper über verschiedene AI Governance Initiativen, an dem ich mitgewirkt habe. Der Text ist als Preprint verfügbar oder kann über folgenden Link eingesehen werden.
I wrote a report with a group of fantastic international collaborators including @DrMoniqueMann @VidushiMarda @weiwanglaw @benwagne_r on AI, Ethics and Governance, which was released today at #MWC19 in Shanghai.
Check out the full text here: https://t.co/yHJsNliSCB
— (Dr) Angela Daly | 李安琪 (@nidhalaigh) 28. Juni 2019
Neuer Aufsatz – What AI (currently) can’t do
In AI & Society erschien jüngst mein neuer Aufsatz über aktuelle Limitationen und Herausforderungen bei der Entwicklung und Anwendung künstlicher Intelligenz. Der Aufsatz beschreibt in einer Übersicht fünfzehn verschiedene Bereiche, in denen methodologische, gesellschaftliche oder technologische “shortcomings” aktueller KI-Technologie situiert sind. Eingesehen werden kann das Paper unter diesem Link.
Übersichtsartikel zur Ethik der künstlichen Intelligenz
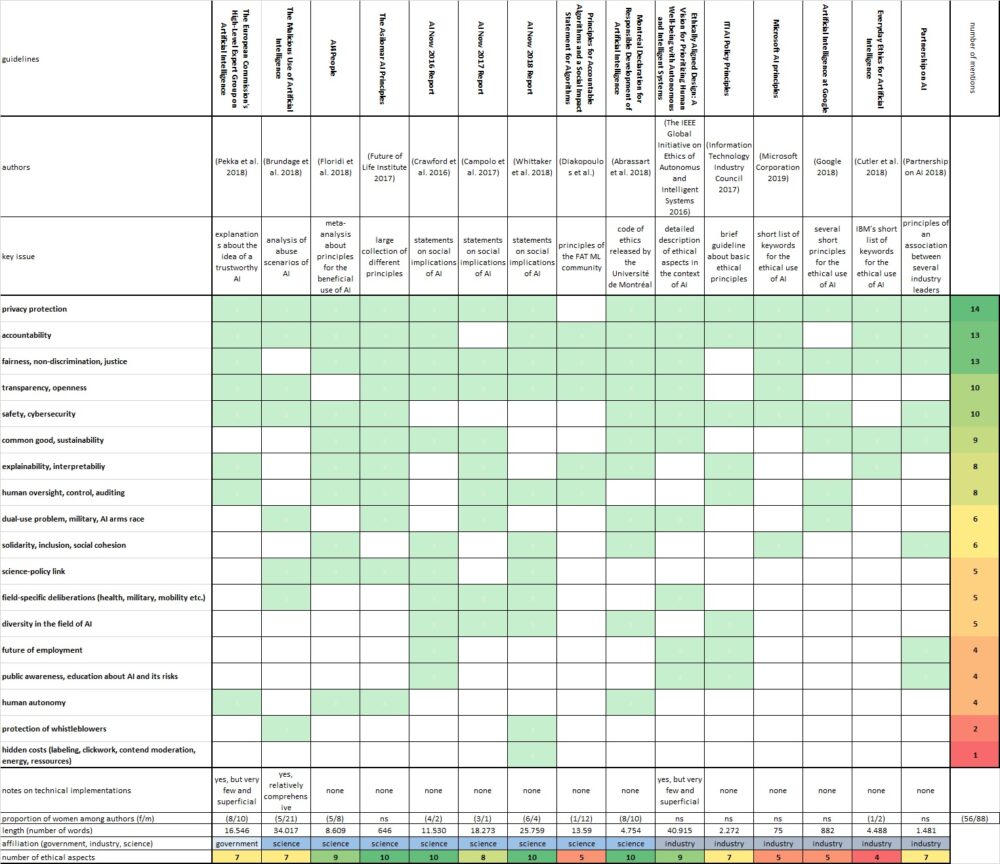
Angesichts der Vielzahl an Richtlinien zur Ethik der künstlichen Intelligenz beziehungsweise des maschinellen Lernens habe ich einen Übersichtsartikel geschrieben, in dem ich die Richtlinien miteinander vergleiche, Gemeinsamkeiten herausarbeite, aber auch Leerstellen benenne und reflektiere, welcher Typus von Ethiktheorie jeweils verfolgt wird. Letztlich beschreibe ich auch, inwiefern die Richtlinien in der Praxis umgesetzt werden können. Das Paper ist bei Minds and Machines erschienen. Es kann unter diesem Link eingesehen werden und ist von der Technology Review zu den “most thought-provoking papers” der dritten Märzwoche gerechnet worden. Anbei zudem das “Herzstück” des Papers, die tabellarische Übersicht über die Ethik-Richtlinien und ihre einzelnen Aspekte.
Privatheit in Zeiten lernender Maschinen
Man stelle sich vor, man liefe an einer Überwachungskamera vorbei und eine Software analysierte allein anhand von Gesichtszügen die eigene sexuelle Orientierung, die Neigung zu kriminellen Handlungen, politische Überzeugungen oder wie vertrauenswürdig, dominant oder intelligent man wirkt. Dies klingt wie Science-Fiction. Ist es aber nur bedingt. Denn tatsächlich entstehen durch die Möglichkeiten moderner Technologien des Maschinenlernens beziehungsweise der künstlichen Intelligenz ungeahnte Möglichkeiten der Datenauswertung. Die Gesichtsanalyse ist dabei nur ein Bereich von vielen. Continue reading “Privatheit in Zeiten lernender Maschinen”